Функционирование сетей APT
Рассмотрим более детально пять фаз процесса функционирования APT: инициализацию, распознавание, сравнение, поиск и обучение.
Инициализация. Перед началом процесса обучения сети все весовые векторы



Веса векторов

где


— константа, большая 1 (обычно

Эта величина является критической; если она слишком большая, сеть может распределить все нейроны распознающего слоя одному входному вектору.
Веса векторов

Эти значения также являются критическими; показано, что слишком маленькие веса приводят к отсутствию соответствия в слое сравнения и отсутствию обучения.
Параметр сходства

инициализирует фазу распознавания. Так как вначале выходной вектор слоя распознавания отсутствует, сигнал


Как обсуждалось ранее, распознавание реализуется вычислением свертки для каждого нейрона слоя распознавания, определяемой следующим выражением:

где




где

В соответствии с алгоритмом обучения возможно, что другой нейрон в слое распознавания будет обеспечивать более хорошее соответствие, превышая требуемый уровень сходства, несмотря на то, что свертка между его весовым вектором и входным вектором может иметь меньшее значение. Пример такой ситуации показан ниже.
Если сходство ниже требуемого уровня, запомненные образы могут быть просмотрены, чтобы найти образ, наиболее соответствующий входному вектору. Если такой образ отсутствует, вводится новый несвязанный нейрон, который в дальнейшем будет обучен. Чтобы инициализировать поиск, сигнал сброса тормозит возбужденный нейрон в слое распознавания на время проведения поиска, сигнал
устанавливается в единицу и другой нейрон в слое распознавания выигрывает соревнование. Его запомненный образ затем проверяется на сходство, и процесс повторяется до тех пор, пока конкуренцию не выиграет нейрон из слоя распознавания со сходством, большим требуемого уровня (успешный поиск), либо пока все связанные нейроны не будут проверены и заторможены (неудачный поиск).
Неудачный поиск будет автоматически завершаться на несвязанном нейроне, так как его веса все равны единице, своему начальному значению. Поэтому правило двух третей приведет к идентичности вектора
входному вектору

Обучение. Обучение представляет собой процесс, в котором набор входных векторов подается последовательно на вход сети, а веса сети изменяются при этом таким образом, чтобы сходные векторы активизировали соответствующие им нейроны. Заметим, что это - неуправляемое обучение, здесь нет учителя и нет целевого вектора, определяющего требуемый ответ.
Различают два вида обучения: медленное и быстрое. При медленном обучении входной вектор предъявляется настолько кратковременно, что веса сети не успевают достигнуть своих ассимптотических значений при единичном предъявлении. В этом случае значения весов будут определяться, скорее, статистическими характеристиками входных векторов, чем характеристиками какого-то одного входного вектора.
Динамика сети в процессе медленного обучения описывается дифференциальными уравнениями.
Быстрое обучение является специальным случаем медленного обучения, когда входной вектор прикладывается на достаточно длительный срок, чтобы позволить весам приблизиться к их окончательным значениям. В этом случае процесс обучения описывается только алгебраическими выражениями. Кроме того, компоненты весовых векторов
Рассмотренный далее обучающий алгоритм используется как в случае успешного, так и в случае неуспешного поиска.
Пусть вектор весов
распознающего слоя) равен нормализованной величине вектора

где



Компоненты вектора весов

где

Характеристики АРТ
Системы APT имеют ряд важных характеристик, не являющихся очевидными. Формулы и алгоритмы могут казаться произвольными, в то время как в действительности они были тщательно отобраны и соответствуют требованиям теорем относительно производительности систем APT. В данном разделе описываются некоторые алгоритмы APT, раскрывающие отдельные вопросы инициализации и обучения.
Инициализация весов bij
Инициализация весов
Установка этих весов в малые величины гарантирует, что несвязанные нейроны не будут получать возбуждения большего, чем обученные нейроны в слое распознавания. Используя предыдущий пример с






Поиск. Может показаться, что в описанных алгоритмах отсутствует необходимость фазы поиска, за исключением случая, когда для входного вектора должен быть распределен новый несвязанный нейрон. Это не совсем так: предъявление входного вектора, сходного, но не абсолютно идентичного одному из запомненных образов, может при первом испытании не обеспечить выбор нейрона слоя распознавания с уровнем сходства, большим р, хотя такой нейрон будет существовать; и, тем самым, без поиска не обойтись.
Как и в предыдущем примере, предположим, что сеть обучается следующим двум векторам:

с векторами весов


Теперь приложим входной вектор

будет равно 1/2. Если уровень сходства установлен в 3/4, нейрон 1 будет заторможен и нейрон 2 выиграет состязание.
станет равным 1, критерий сходства будет удовлетворен, и поиск закончится.
Инициализация весовых векторов T
В ранее рассмотренном примере обучения сети можно было видеть, что правило двух третей приводит к вычислению вектора
Это объясняет, почему веса
Обучение может рассматриваться как процесс "сокращения" компонент запомненных векторов, которые не соответствуют входным векторам. Процесс необратим, если вес однажды установлен в нуль, — обучающий алгоритм никогда не восстановит его единичное значение.
Это свойство имеет важное отношение к процессу обучения. Предположим, что группа точно соответствующих векторов должна быть классифицирована как одна категория, определяемая возбуждением одного нейрона в слое распознавания. Если эти векторы последовательно предъявляются сети, то при предъявлении первого будет распределяться нейрон распознающего слоя и его веса будут обучены с целью соответствия входному вектору. Обучение при предъявлении остальных векторов будет приводить к обнулению весов в тех позициях, которые имеют нулевые значения в любом из входных векторов. Таким образом, запомненный вектор представляет собой логическое пересечение всех обучающих векторов и может включать существенные характеристики данной категории весов. Новый вектор, включающий только существенные характеристики, будет соответствовать этой категории. Таким образом, сеть корректно распознает образ, никогда не виденный ранее, т. е. реализуется возможность, напоминающая процесс восприятия в мозге человека.
Настройка весовых векторов Bj
Выражение, описывающее процесс настройки весов, является центральным для описания процесса функционирования сетей APT:

Сумма в знаменателе представляет собой количество единиц на выходе слоя сравнения. Заданная величина может быть рассмотрена как "размер" этого вектора. В такой интерпретации "большие" векторы
Чтобы проиллюстрировать проблему, которая возникает при отсутствии масштабирования, используемого в данном выражении, предположим, что сеть обучена двум приведенным ниже входным векторам, при этом каждому распределен нейрон в слое распознавания.
Заметим, что
прикладывается повторно, оба нейрона в слое распознавания получают одинаковые активации; следовательно, нейрон 2 — ошибочный нейрон — выиграет конкуренцию.
Кроме выполнения некорректной классификации, может быть нарушен процесс обучения. Так как


Масштабирование весов

Подавая на вход сети вектор

Нерешенные проблемы и недостатки АРТ-1
Нейронные сети АРТ, при всех их замечательных свойствах, имеют ряд недостатков. Один из них — большое количество синаптических связей в сети, в расчете на единицу запоминаемой информации. При этом многие из весов этих связей (например, вектора
Сеть АРТ-1 приспособлена к работе только с битовыми векторами. Это неудобство преодолевается в сетях АРТ-2 и АРТ-3. Однако в этих архитектурах, равно как и в АРТ-1, сохраняется главный недостаток АРТ — локализованность памяти. Память нейросети АРТ не является распределенной, и некоторой заданной категории отвечает вполне конкретный нейрон слоя распознавания. При его разрушении теряется память обо всей категории. Эта особенность, увы, не позволяет говорить о сетях адаптивной резонансной теории как о прямых моделях биологических нейронных сетей. Память последних является распределенной.
Пример обучения сети АРТ
В общих чертах сеть обучается при помощи изменения весов таким образом, что предъявление входного вектора заставляет сеть активизировать нейроны в слое распознавания, связанные со сходным запомненным вектором. Кроме этого, обучение проводится в форме, не разрушающей запомненные ранее образы, и предотвращает тем самым временную нестабильность. Эта задача управляется на уровне выбора критерия сходства. Новый входной образ (который сеть раньше не видела) не будет соответствовать запомненным образам с точки зрения параметра сходства, тем самым формируя новый запоминаемый образ. Входной образ, в достаточной степени соответствующий одному из запомненных образов, не будет формировать нового экземпляра, он просто будет модифицировать тот, на который он похож. В результате при соответствующем выборе критерия сходства предотвращается запоминание ранее изученных образов и временная нестабильность.
На рис. 12.1 показан типичный сеанс обучения сети APT. Буквы изображены состоящими из маленьких квадратов, каждая буква размерностью

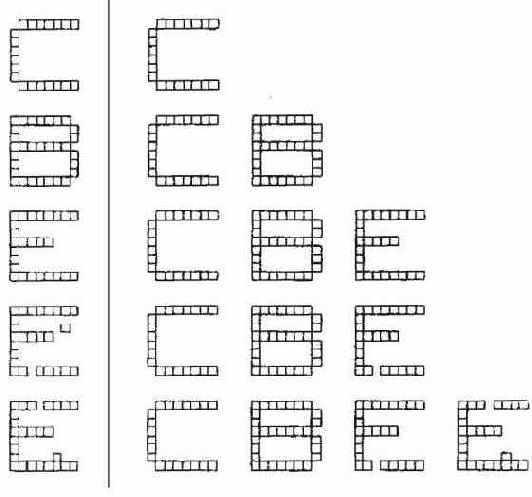
увеличить изображение
Рис. 12.1.
Вначале на вход заново проинициированной системы подается буква "С". Так как отсутствуют запомненные образы, фаза поиска заканчивается неуспешно; новый нейрон выделяется в слое распознавания, и веса
устанавливаются равными соответствующим компонентам входного вектора, при этом веса
Далее предъявляется буква "В". Она также вызывает неуспешное окончание фазы поиска и выделение нового нейрона. Аналогичный процесс повторяется для буквы "Е". Затем слабо искаженная версия буквы "Е" подается на вход сети. Она достаточно точно соответствует запомненной букве "Е", чтобы выдержать проверку на сходство, поэтому используется для обучения сети.
Отсутствующий пиксель в нижней ножке буквы "Е" устанавливает в 0 соответствующую компоненту вектора
Четвертым символом является буква "Е" с двумя различными искажениями. Она не соответствует ранее запомненному образу (
меньше чем
Этот пример иллюстрирует важность выбора корректного значения критерия сходства. Если значение критерия слишком велико, большинство образов не будут подтверждать сходство с ранее запомненными и сеть будет выделять новый нейрон для каждого из них. Такой процесс приводит к плохому обобщению в сети, в результате даже незначительные изменения одного образа будут создавать отдельные новые категории; далее количество категорий увеличивается, все доступные нейроны распределяются, и способность системы к восприятию новых данных теряется. Наоборот, если критерий сходства слишком мал, сильно различающиеся образы будут группироваться вместе, искажая запомненный образ, до тех пор, пока в результате не получится очень малое сходство с одним из них.
К сожалению, отсутствует теоретическое обоснование выбора критерия сходства, и в каждом конкретном случае необходимо решить "волевым усилием", какая степень сходства должна быть принята для отнесения образов к одной категории. Границы между категориями часто неясны, и решение задачи для большого набора входных векторов может быть чрезмерно трудным.
Гроссберг предложил процедуру с использованием обратной связи для настройки коэффициента сходства, вносящую, однако, некоторые искажения в результаты классификации как "наказание" за внешнее вмешательство с целью увеличения коэффициента сходства. Такие системы требуют правил оценки корректности для производимой ими классификации.
Теоремы APT
Гроссберг доказал некоторые теоремы, которые описывают характеристики сетей APT. Четыре результата, приведенные ниже, являются одними из наиболее важных:
После стабилизации процесса обучения предъявление одного из обучающих векторов (или вектора с существенными характеристиками категории) будет активизировать требуемый нейрон слоя распознавания без поиска. Такая характеристика "прямого доступа" обеспечивает быстрый доступ к предварительно изученным образам.Процесс поиска является устойчивым. После определения выигравшего нейрона в сети не будет возбуждений других нейронов из-за изменения векторов выхода слоя сравнения